WordPressからHugoへ:全投稿をMarkdownにエクスポートする (1)
WordPressから記事とアイキャッチ画像の情報をXMLでエクスポートし、パースしてみよう

WordPressからHugoのような静的サイトジェネレーターに移行するには、投稿をMarkdownに変換する必要があります。Hugoの場合、最初の数行にタイトル、投稿日時、公開されているか否かといった Frontmatter という情報をYAML形式で書いておく必要があります。
この作業を簡単にするために、HugoサイトにはWordPressからの移行のためのプラグインや、変換のためのPython、Node.jsスクリプトなどが提供されていますが、私の場合はエラーが生じたりなどといった事情があってこの作業を自前でスクリプトを作って行いました。もしこれらのツールで終わるならばそれに越したことはありませんので、まずはチェックしてみてください。
今回の目標
今回は、WordPressから記事とアイキャッチの情報をエクスポートして、それぞれの記事について Hugo の Frontmatter を出力するところまでやってみます。最終的には、それぞれの記事について次のようなテキストが作れればいいわけです。
---
title: 'タイトル'
date: 2018-06-24T01:43:48+09:00
featured_image: featured.jpg
categories: Hugo
tags: ["Twitter","Instagram"]
draft: false
---
前回の記事で紹介していなかった行として、featured_image があります。これはその名の通りで、ここに書かれたファイル名の画像をアイキャッチとして利用するという設定です。
このあとに、Markdown化した記事の本文が続けば、Hugo で表示することが可能ですので、まずはこの Frontmatter を処理しましょう。
WordPressからXML形式で投稿とアイキャッチ画像情報をエクスポート
まず、WordPressの管理画面から、「ツール」→「エクスポート」を選択して、情報を eXtended RSS (WXR) 形式で保存するページを開きます。ここで「すべてのコンテンツ」を選択してエクスポートファイルができたなら上出来です。
もしわたしのように失敗したときは、「投稿」についてのみエクスポートするのと、「メディア」についてのみエクスポートするという具合に二回に分けてみてください。
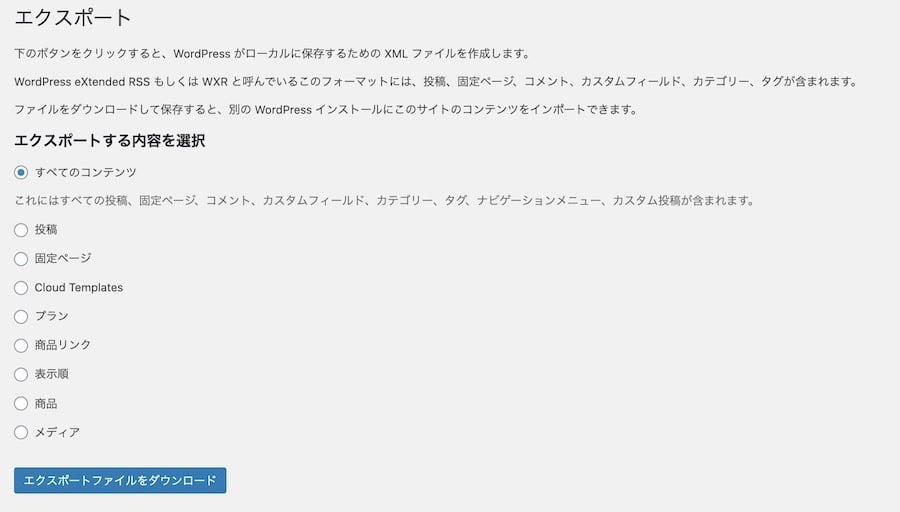
エクスポートされたXMLファイルを理解する
このファイルは RSS 形式のような XML で記述されていて、テキストファイルを開くと item というタグで分割された情報が一つ一つの記事の内容を内包していることがわかります。
<item>
<title>一時的にSNSを遮断したいときに利用できるStayFocusdとFreedom</title>
<link>https://lifehacking.jp/2020/04/stayfocusd-freedom/</link>
<pubDate>Tue, 14 Apr 2020 06:34:49 +0000</pubDate>
<dc:creator><![CDATA[eddie]]></dc:creator>
<guid isPermaLink="false">https://lifehacking.jp/?p=26765</guid>
<description></description>
<content:encoded><![CDATA[<!-- wp:paragraph -->
<p>本文</p>
</content:encoded>
<excerpt:encoded><![CDATA[]]></excerpt:encoded>
<wp:post_id>26765</wp:post_id>
<wp:post_date><![CDATA[2020-04-14 15:34:49]]></wp:post_date>
<wp:post_name><![CDATA[stayfocusd-freedom]]></wp:post_name>
<wp:status><![CDATA[publish]]></wp:status>
<wp:post_type><![CDATA[post]]></wp:post_type>
︙
<title> タグで囲まれているのはタイトルですし、<content:encoded> というタグにCDATAでくくられているのが本文だとわかります。ここまでは簡単ですね。
ちょっと面倒なのはアイキャッチ画像の情報で、それは記事本文よりもさらに下のほうに、<wp:postmeta>というタグでメタ情報の部分に保存されています。
<wp:postmeta>
<wp:meta_key><![CDATA[_thumbnail_id]]></wp:meta_key>
<wp:meta_value><![CDATA[26776]]></wp:meta_value>
</wp:postmeta>
複数ある <wp:meta_key> のうち、_thumbnail_id というキーの値として保存されている26776 という数字がそれです。画像もブログ投稿と同様に一つ一つに <wp:post_id> が割り振られていますので、これを同じ XML の中から探します(メディアを別ファイルでエクスポートしているならそこから)。
<item>
<title>freedom</title>
<link>https://lifehacking.jp/2020/04/stayfocusd-freedom/freedom/</link>
<pubDate>Tue, 14 Apr 2020 06:15:37 +0000</pubDate>
<dc:creator><![CDATA[eddie]]></dc:creator>
<guid isPermaLink="false">https://lifehacking.jp/wp-content/uploads/2020/04/freedom.jpg</guid>
<wp:post_id>26776</wp:post_id>
<wp:post_date><![CDATA[2020-04-14 15:15:37]]></wp:post_date>
<wp:post_date_gmt><![CDATA[2020-04-14 06:15:37]]></wp:post_date_gmt>
<wp:post_name><![CDATA[freedom]]></wp:post_name>
<wp:post_type><![CDATA[attachment]]></wp:post_type>
<wp:attachment_url><![CDATA[https://lifehacking.jp/wp-content/uploads/2020/04/freedom.jpg]]></wp:attachment_url>
︙
これが <wp:post_id> が 26766 に対応したレコードです。ここで、<wp:attachment_url> というタグのなかに、画像への URL が記述されています。
よくみると、<item> タグで囲まれた情報について、ブログ投稿は <wp:post_type> が post に、画像は attachment になっているのがわかります。
というわけで、このファイルをパースするときの方針として:
- xmlファイル中のすべての <item> タグを取り出して <wp:post_type> が attachment ならばそれは画像情報なので <wp:attachment_url> の内容を一時保存しておく
- もういちど xml ファイルをすべての <item> タグについて見て、今度は <wp:post_type> が post ならばそれは記事なので <title>、<pubDate>、<wp:post_name>、そして post_id に対応したアイキャッチ画像の <wp:attachment_url>、そして本文を元にMarkdownを作る
という流れになることがわかります。必要ならば <wp:status> の値によって投稿状態をドラフトにしたり、変更日を追加するといったこともできますが、今回はdraftの値はすべてfalseにして、最初から公開されているようにします。
xmllint をかけておく
WordPressからエクスポートしたxmlファイルはゴミが混じっていることがほとんどですので、xmlint をかけてあらかじめ除去しておきます。20MBくらいのファイルなら、テキストエディタでもぎりぎり編集できるでしょうからその手を使います。
xmlint all-post.xml
コマンドを実行するとそれなりの数のエラーとその行番号が見つかるかと思いますので、修正していきます。わたしの20MBのXMLの場合、15箇所ほどになりました。
<content:encoded><![CDATA[WordPress をインストールして^H作業を開始中です。
こういうのですね。たとえば改行コードが変になっていたり、^H といったバックスペースの制御コードが混じっていることがたまにあります。
すべてを修正すると、xmllint は xml ファイル自体を表示して正常終了するので、そうなるまで修正します。
アイキャッチ画像のURLをパースする
まず、すべてのアイキャッチ画像のURLを取り出すところまでを Pythonで書いてみます。ElementTree でパースしますが、名前空間があるので最初にすべて定義しておきます。
import xml.etree.ElementTree as et
# define namespace
ns = { 'excerpt': 'http://wordpress.org/export/1.2/excerpt/',
'content': 'http://purl.org/rss/1.0/modules/content/',
'wfw': 'http://wellformedweb.org/CommentAPI/',
'dc': 'http://purl.org/dc/elements/1.1/',
'wp': 'http://wordpress.org/export/1.2/' }
# parse xml
tree = et.parse('export.xml')
root = tree.getroot()
# get each attachment and post
featured_img = {}
for i in root.iterfind('./channel//item',ns):
type = i.find('.//wp:post_type',ns).text
# make a dict of all featured images
if (type == 'attachment'):
id = i.find('.//wp:post_id',ns).text
url = i.find('.//wp:attachment_url',ns).text
featured_img[id] = url
︙
あとは root.iterfind を使って channel タグの下に複数ある item タグでループを作り、<wp:post_type> が attachment なら、<wp:post_id> をキーとして <wp:attachment_url> を featured_img のなかに保存しておきます。
すべての記事について情報を取り出す
今度は同じループを、<wp:post_type> が post であるときを探して回します。その直下に Frontmatter を使うのに必要な情報が揃っていますので、find メソッドで拾い集めています。
for i in root.iterfind('./channel//item',ns):
type = i.find('.//wp:post_type',ns).text
if (type == 'post'):
id = i.find('.//wp:post_id',ns).text
title = i.find('.//title',ns).text
content = i.find('.//content:encoded',ns).text
pubdate = i.find('.//pubDate',ns).text
post_name = i.find('.//wp:post_name',ns).text
for m in i.iterfind('./wp:postmeta',ns):
meta_key = m.find('./wp:meta_key',ns)
meta_val = m.find('./wp:meta_value',ns)
if (meta_key.text == "_thumbnail_id"):
featured = featured_img[meta_val.text]
︙
複数存在するカテゴリやタグをまとめておく
タグとカテゴリは item タグ直下に順不同で以下のように並んでいます。
<category domain="category" nicename="gtd"><![CDATA[GTD]]></category>
<category domain="category" nicename="webservice"><![CDATA[ウェブサービス]]></category>
<category domain="post_tag" nicename="lifehack"><![CDATA[ライフハック]]></category>
なので、XML をパースする際にはcategoryというタグを探し、domain アトリビュートがそれぞれの値の場合にリストに加えておきます。
# get all category
cat_list = []
for c in i.iterfind('.//category[@domain="category"]',ns):
cat_list.append(c.text)
# get all tag
tag_list = []
for c in i.iterfind('.//category[@domain="post_tag"]',ns):
tag_list.append(c.text)
日付を RFC822 から iso 形式に変換する
WordPressのXMLでpubDateにかかれている時刻は “Tue, 30 Apr 2013 16:29:09 +0000” という形式になっています。メールなどで使われるフォーマットで、しかも +0000 ということでUTCになっています。
しかしブログでパーマリンクを作ったりする場合、例えば 2020/04/01 という日付はブログの設定、これを読んでいる多くの人にとっては日本標準時で発行されますので、うっかりすると日付がずれたりするようです。
また、Hugo の frontmatter で使用しているのは “2018-02-23T17:10:03+0900” といった iso 形式になりますので、これも同時に対応させておきます。
“2020-04-01” だけでもいいのですが、過去に一日に二回以上更新した時があるなら、順序が入れ替わったりするのは嫌ですので時刻は正確にしておきます。
import datetime
import email.utils
import pytz
date = email.utils.parsedate_tz(str(pubdate))
dt = datetime.datetime( date[0], date[1], date[2], date[3], date[4], date[5] )
dt = pytz.utc.localize(dt).astimezone(pytz.timezone("Asia/Tokyo"))
pubdate = dt.isoformat(timespec="seconds")
Hugo の Frontmatter を出力する
それではここまで取得した情報を、item タグのたびに出力してみましょう。アイキャッチ画像がない場合の対応、カテゴリとタグについてはコンマでつなぐことをして、以下のようなコードになります。
# print frontmatter
print("---")
print("title: \'" + title + "\'")
print("date: " + pubdate)
if featured:
featured = os.path.basename(featured)
print("featured_image: " + featured)
if cat_list:
print("categories: ["+','.join('"{0}"'.format(x) for x in cat_list)+"]")
if tag_list:
print("tags: ["+','.join('"{0}"'.format(x) for x in tag_list)+"]")
print("draft: false")
print("---\n")
すると、次のような出力がでてきます。
---
title: 'インスタグラムの縦型動画「IGTV」をFinal Cut Pro Xで簡単につくる #IGTV'
date: 2018-06-24T01:43:48+09:00
featured_image: igtv.jpg
categories: Hugo
tags: ["IGTV","Instagram"]
draft: false
---
featured_image からパスを消してファイル名だけにしているのは、あとでこのファイルを記事のフォルダにコピーするつもりだからです。また、すべての記事がドラフトではなく、公開状態であるという想定で作っています。もし初期状態で全部ドラフトにしておきたいなら、false の部分を true にしておきます。
今回は多少の想定が入っていますので、失敗するケースもあります。たとえばタイトルに引用符が入っていたりした場合などは、あとで Hugo がエラーを起こす可能性がありますが、そうしたケースは数が少ないので今回のスクリプトではいちいち修正していません。
これで、Frontmatter が書けましたので、このあとに記事をMarkdown に変換して付け足せばいいわけです。それについては次回。
今回作った途中経過のスクリプトはこちらの Gist にありますので、自由に使ってください(結果やエラーについては保証できませんのでご注意ください)。
