WordPressからHugoへ:全投稿をMarkdownにエクスポートする (3)
これまでの情報を総合して、すべての記事をMarkdown化するとともに、関係した画像ファイルをコピーして集めましょう

前回と前々回で、WordPressから出力したXMLファイルを元にしてHugoの記事の元となるFrontmatterとMarkdown形式の本文を抽出することに成功しました。
いよいよ、すべての記事を変換する作業をおこないますが、同時にフォルダの構成や画像の置き場所なども変えてしまいましょう。
最終的なファイルとディレクトリの構成を考える
Hugoはとても柔軟性が高いので、ここに示しているのは「こんなことが可能だ」という一つの例に過ぎませんが、今回はいろいろと考えがあって次のようなディレクトリ構成と、ファイル構成を考えました。
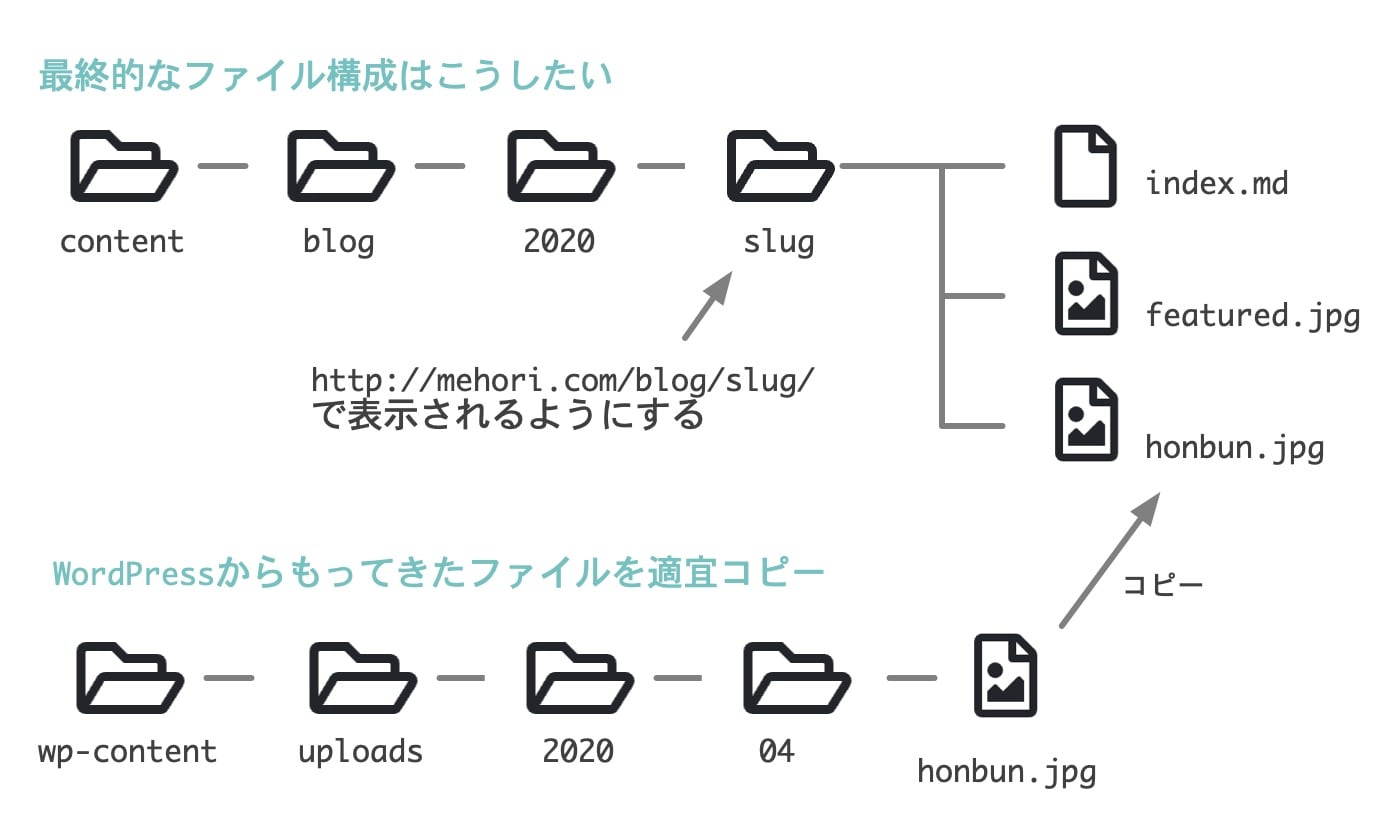
まず、Hugo で表示されるコンテンツはすべて content という名前のディレクトリに入っています。このディレクトリに入っているトップレベルのディレクトリは、Section という特別な扱いになります。たとえばここでは blog というディレクトリがありますので、あとでテーマを作る際に「blog というタイプの投稿だけを表示して」などと制御できます。
blog の下のディレクトリでは、index.md というファイルが存在するディレクトリだけが自動的に記事になります。そのとき、パーマリンクの名前はそのフォルダ名になるように設定します。つまり、slug というディレクトリのなかに index.md がありますので、この記事は http://mehori.com/blog/slug でアクセスできるわけです。
では 2020 というフォルダはどうでしょうか? http://mehori.com/blog/2020 にアクセスしたときに 2020 年の記事をすべて表示させるようにしたり、特別なページを見せることもできますが、なにも表示されないようにもできます。
こうすることで、content というディレクトリに何百個も記事のディレクトリがぶらさがるのではなく、年ごとに整理できるようにしてみました。もちろん、これ以外の構成も設定次第で自在にできます。
また、WordPressからftpでとっておいたwp-contentフォルダを用意しておいて、Markdownファイルのなかに画像の参照があるたびに、それを slug というディレクトリにコピーするようにしておきます。こうすれば、記事と画像を同じ場所で管理して、要らなくなったらフォルダごとゴミ箱に入れるだけで記事が削除できます。
ディレクトリを作り、ファイルをコピーしつつMarkdownを書き出し
それでは前回と、前々回のスクリプトに手を加えて、これを実現してみましょう。具体的には:
- WordPressのxmlファイルをパースして画像の位置を確認しておく(前々回の内容)
- WordPressのxmlファイルをパースして、記事の基本情報を確保しておく(前々回の内容)
- それぞれの記事について、本文をMarkdownに変換(前回の内容)
- 記事の年号に従って、ディレクトリがなければ作成
- 記事の名前に従って、ディレクトリを作成(図のslugに相当)
- アイキャッチがあったら、wp-uploadからslugにコピー
- Markdownの本文中に画像タグがあったら、やはりwp-uploadからコピー
- Markdownを適宜変更して、slugディレクトリにindex.mdを書き出し
という処理を行います。
まず、前回記事の投稿時間を取得した場所で年を year という変数に取り出して文字列として保存しておきます。
date = email.utils.parsedate_tz(str(pubdate))
year = str(date[0])
次に、もし年号のディレクトリがないなら作成し、そこに記事のディレクトリを作ります。今回は日本語で書かれたパーマリンクは想定していませんが、おそらく URL エンコードされた日本語を戻しながら処理すれば大丈夫なはずです。
# mkdir: year
odir = "./out/"
if not os.path.isdir(odir+year):
os.mkdir('./out/'+year)
# mkdir each post
if not os.path.isdir(odir+year+"/"+str(post_name)):
os.mkdir('./out/'+year+"/"+str(post_name))
with open('./out/'+ year + "/" + str(post_name)+"/index.md", 'w') as f:
# print frontmatter
print("---",file=f)
print("title: \'" + title + "\'",file=f)
print("date: " + pubdate,file=f)
︙
最後に記事をMarkdownに変換して、画像をコピーしていきます。
# find image within content
match = re.findall(r'!\[.*?]\((?:http|https)://lifehacking\.jp/wp-content/uploads/(.*?)\)',str(content))
for m in match:
src_file = 'uploads/'+m
bn = os.path.basename(m)
dst_file = './out/'+ year + "/" + str(post_name)+'/'+bn
if (os.path.exists(src_file)):
copyfile(src_file,dst_file)
else:
print("no file within post:",src_file," at ",post_name)
# replace all image markdown url
content = re.sub(r'!\[(.*?)]\((?:http|https)://lifehacking\.jp/wp-content/uploads/.*/(.*?)\)','',str(content))
print(content,file=f)
この部分の最初の正規表現では、ファイルをどこからコピーすればいいのかのパスを取り出して、存在するようならばコピーを行っています。

このような感じですね。2番目の正規表現は最終的な記事の本文に置換を加えているものです。
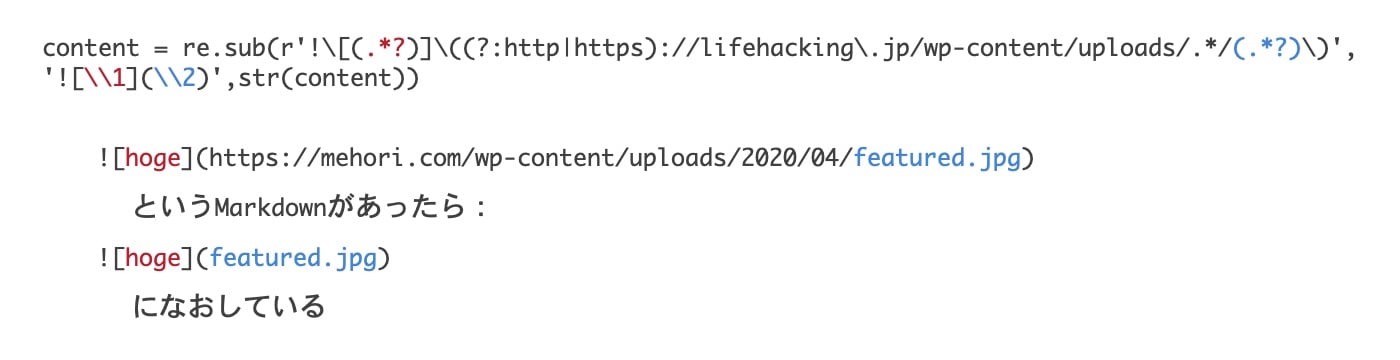
荒っぽいですが、結果は得られます。これで、記事内に存在したドメインやフォルダ構造の相対パスがすべて消えて、画像のファイル名だけが残りました。これで大丈夫なところがHugoを始めとする静的サイトジェネレーターのいいところですね。
起こりうるエラー
現時点ではタイトルの引用符の扱いが雑ですので、まれに 「’」が含まれている記事がある場合に Hugo がエラーになるケースがあるかと思います。そうしたときはタイトルを囲んでいる引用符を「"」にしてください。エスケープをちゃんとすればいいのです面倒で…。
本スクリプトを使う前に
これで、WordPressからhugoで使用できるMarkdown形式のファイルを、自分好みのディレクトリ構成で作ることができました。今回のスクリプトもGistに置いておきますが、もちろんこのまま使うことはできません。
- mehori.com がハードコードされているところは自分のドメインに変更してください
- このスクリプトのあるディレクトリに out というディレクトリを作成してください。またスクリプトを走らせるたびに out の内容は削除してください。
- WordPressの画像が入っているuploadsディレクトリを同じディレクトリに置いてください
日本語パーマーリンク、草稿、固定ページといった、ここでは想定していないものがあると、予想外の挙動をするかもしれません。ファイル構造を作ったり、大量のファイルを作ったりしますので、取り扱いには注意して、上の解説を読んで何をしているか理解してから使用してみてください。
ここまで読めた人ならば、おそらくこれを改変して、自分の好みに置き換えることも難しくないはずです。
